
티스토리 뷰
선형회귀의 모델 적합성을 검증하는 과정에서, 작년에 수강한 기초통계학 시간에 배웠던 통계적 추론 내용이 나와 복습하고자 한다.
1. 통계적 추론이란
통계적 추론이란 표본이 갖고 있는 정보를 분석하여 모수에 관한 결론을 유도하고. 모수에 대한 가설의 옳고 그름을 판단하는 것을 말한다.
통계학 파이썬을 이용한 분석(자유아카데미)
교재에는 위와 같이 서술되어 있다.
쉽게 설명하자면 전체 모집단에서 일부를 추출한 표본의 정보만을 가지고 분석하여 (통계적으로 추론하여) 모수에 대해 알아보는 것이다.
통계적 추론은 크게 모수의 추정(estimation)과 모수에 대한 가설검정(test of hypothesis)로 나누어 볼 수 있다.
★지금부터의 내용은 표본의 크기가 크다는 전제하에 서술된다.
2. 모수의 추정
(1) 점추정(Point Estimation)
점추정이란 추정하고자 하는 하나의 모수에 대하여 임의로 추출된 n개의 확률변수로 하나의 통계량을 만들고, 주어진 표본으로부터 그 값을 계산하여 하나의 수치를 제시하려고 하는 것이다.
통계학 파이썬을 이용한 분석(자유아카데미)
이때 모수를 추정하기 위해 만들어진 통계량을 추정량(estimator)라 하고 계산된 추정량의 값을 추정치(estimate)라 한다.
(※ estimator: 모수를 나타내는 함수, estimates: 값)
예를 들어 모평균(우리나라의 4인 가구 기준 올해 8월 지출의 평균)을 추정한다고 할 때, 어느 도시의 4인 가구 지출액의 평균 즉, 표본평균이 추정량이 되고 추정치는 400만원이 될 수 있다.
하지만 표본을 새로 뽑을 때마다 추정량이 바뀔텐데, 이런 수치들의 변화는 추정량의 정확도와 관계가 있다. 이 정확도를 측정하는 하나의 도구로 표준오차(standard error, S.E.)라고 하는 추정량의 표준편차가 있다. 명칭 그대로 표준오차가 작을수록 정확하다는 것을 의미한다.
표본평균의 기댓값과 표준오차는 모집단의 평균과 표준편차가 각각 μ와 б일 때 다음과 같이 구할 수 있다.

따라서 n이 클수록 표준오차가 작아져 더 정확히 μ를 추정할 수 있지만, 실제로 б가 주어져 있지 않은 경우가 많다.
이때 б를 표본표준편차 s로 추정하여 사용할 수 있다.

즉, 표준오차가

라면, 추정된 표준오차는

이다.
(2) 구간추정(Inverval Estimation)
구간추정은 하나의 수치를 구하는 것이 아니라 추정량의 분포를 이용하여 표본으로부터 모수 값을 포함하리라고 예상되는 구간을 구하여 제시하는 것이다.
통계학 파이썬을 이용한 분석(자유아카데미)
이때 제시되는 구간을 신뢰구간(confidence interval)이라고 한다.
신뢰구간은 표본으로부터 통계량을 계산하므로 표본마다 계산되는 신뢰구간은 서로 다를 수 있다.
모평균에 대한 정확한 정보를 얻기 위해 신뢰구간을 가능한 한 줄일 필요가 있는데,
(모수를 포함할 확률이 1이라면 신뢰구간이 (-∞,∞)도 될 수 있다.)
이를 위해 모수를 포함할 확률을 1이 아니라 90%나 95%로 완화시킨다. 이러한 확률을 신뢰수준(level of confidence) 또는 신뢰도라고 한다.

이므로, 표준화된 표본평균은 표준정규분포 N(0,1)를 따르고 다음과 같이 나타낼 수 있다.
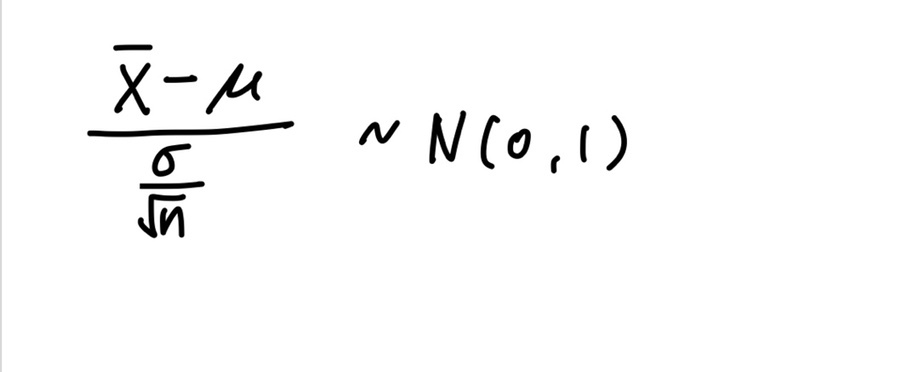
다음과 같이 전개할 수 있다.
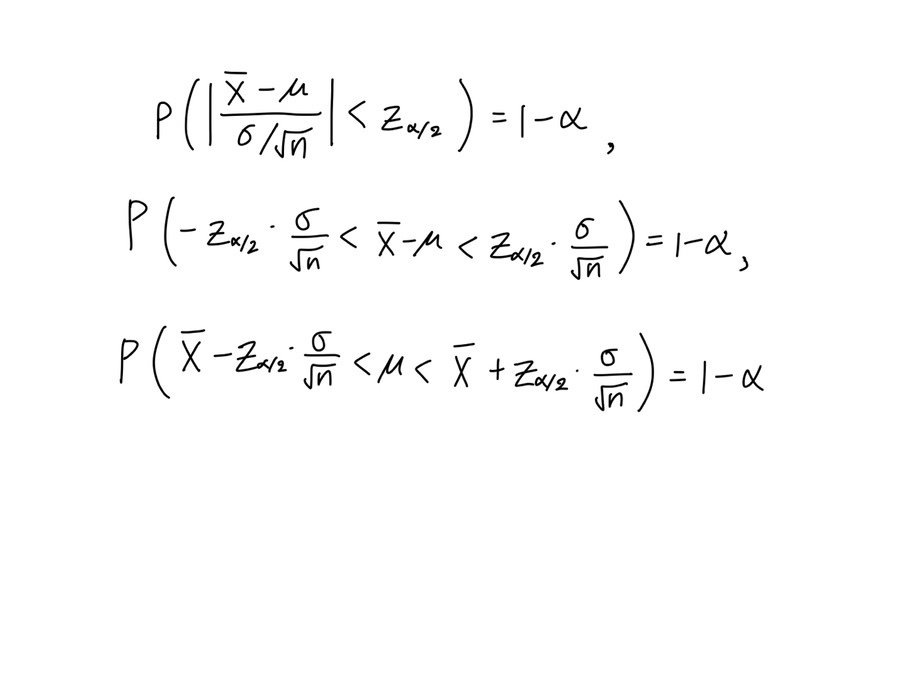
이를 통해 모수 μ가 신뢰구간 안에 포함될 확률이 1-α 임을 예상할 수 있다.
이때
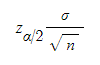
를 100(1-α)% 오차범위(error margin)라고 한다.
따라서 б가 작을수록 신뢰구간의 길이가 짧아지고, α 를 줄일수록 신뢰구간의 길이가 길어진다. 또한 표본의 크기가 클수록 신뢰구간의 길이가 짧아지므로 μ에 대한 좀 더 정확한 정보를 얻을 수 있다.
이때 95% 신뢰구간이라고 가정할 때, 이것이 의미하는 것은 95%의 확률로 μ를 포함한다는 것이 아니다. 같은 크기의 표본을 여러 번 추출하여 같은 공식에 의한 신뢰구간을 구할 경우에 그 중 약 95%의 구간이 모수를 포함하리라고 예상할 수 있다는 것이다.
쉽게 이야기하자면 표본을 100번 추출하여 나온 100개의 신뢰구간을 비교하였을 때, 100개 중 약 95개의 신뢰구간이 모수를 포함하는 것을 의미한다.
3. 가설검정(testing statistical hypotheses)
가설검정이란 모수에 대한 가설이 적합한지를 추출한 표본으로부터 판단하고자 하는 것이다.
통계학 파이썬을 이용한 분석(자유아카데미)
쉬운 설명을 위해 예시를 들고자 한다.
어느 도시의 보건당국에서 여러 성인병을 유발하는 높은 콜레스테롤 수치를 낮추고자, 지난 1년간 콜레스테롤 수치 낮추기 캠페인을 벌였다. 이 캠페인이 효과가 있었는지 검증하고자 그 도시 성인 40명을 대상으로 콜레스테롤 수치를 측정하여 그 평균을 계산하였다.
캠페인 시작 전(시작할 당시) 그 도시 성인의 콜레스테롤 수치는 평균적으로 200(mg/dl)이고 표준편차는 24(mg/dl)인 분포를 따른다고 알려져 있다고 하자.
이때 캠페인으로 인해서 콜레스테롤 수치가 낮아졌는지 판단하기 위해서 어떠한 과정을 거쳐야할까?
캠페인을 실시한 이후의 그 도시 성인의 콜레스테롤 수치의 모평균을 μ 라고 하자. 이 μ값을 알기 위해서는 그 도시의 모든 성인을 검사해야 가능한데 이는 현실적으로 불가능한 일이다. 이런 이유로 40명의 성인만을 검사하여 표본평균을 구했다 하더라도, 이 값이 실제 μ값과 같은지 알 수 없다.
즉 해당 표본평균으로는 실제 모평균 μ이 200보다 작다고 할 만한 충분한 근거가 있는지 없는지 정도만 이야기할 수 있다.
우선 캠페인이 효과가 없었다고, 즉 μ=200이라고 가정해 보자.
그렇다면 표본인 40명의 콜레스테롤 수치는 캠페인 이전의 성인의 수치와 비슷할 것이고, 따라서 표본의 평균은 200을 중심으로 그 주변의 값을 취하게 될 것이다. 다시말해 표본평균 x̄ 가 200보다 아주 조금 작게 나왔다고 해서 μ가 200보다 작다고 주장할 근거는 되지 못한다. 그러나 x̄ 가 μ=200라면 나오기 힘들 정도로 아주 작은 값을 갖는다면, μ가 200보다 작은 것은 아니었던걸까 생각하게 된다.
그렇다면 x̄가 얼마나 작은 값이 나와야 μ가 200보다 작다고 즉, 캠페인이 효과가 있었다고 주장할 수 있을까?
예를 들어 위와 같이 μ=200 라고 가정했을 때, 표본평균 x̄이 c값(200보다 훨씬 작은 값)보다 적은 값이 나올 확률이 0.05라고 하자. 이때 0.05는 매우 작은 값이므로 표본평균이 실제로 c값보다 작은 값이 나온다면 충분히 μ이 200보다 작다고 주장할 수 있다.
이제 우리가 해야할 일은

가 되는 c값을 찾는 것이다.
이에 답하기 위해서는 x̄의 분포를 알 필요가 있는데, 일단 이 예에서는 모집단이 정규분포를 따른다고 가정하자. 만약 캠페인이 효과가 없었다면 모집단의 분포는
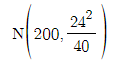
이다.
따라서

이므로 정규분포표로부터

를 이용하여 다음과 같은 식을 얻을 수 있다.

위 식을 계산하면 c = 193.76을 얻을 수 있다. 따라서 경계점 c를 기준으로 다음의 두 가지 결론을 낼 수 있다.
(A) 만약 x̄≤193.76이면 캠페인이 콜레스테롤 수치를 줄이는 데 효과적이라고 할 수 있다.
(B) 만약 x̄>193.76이면 캠페인이 콜레스테롤 수치를 줄이는 데 효과적이라고 할 충분한 근거가 없다.
3-(1) 가설(Hypothesis)
이때 우리가 주장하고자 하는 가설을 대립가설(H1)이라 하고, 대립가설의 반대 가설로 대립가설을 입증할 수 없을 때 대립가설을 무효화시키면서 받아들이는 가설을 귀무가설(H0)라 한다. 위 예시에서 대립가설은 (A)이고, 귀무가설은 (B)라 할 수 있다.
추가로 귀무가설이 맞는데 귀무가설을 기각하는 오류를 제 1종 오류라 하고 귀무가설이 틀렸는데 기각하지 않는 오류를 제 2종 오류라고 한다.
일반적으로 우리가 무언가를 주장할 때는 확실한 증거를 필요로 하기 때문에 제 1종 오류에 더 유의해야 한다. (실제로 우리가 주장하고자 하는 가설(대립가설)이 틀렸는데 그 반대(귀무가설)을 기각하고 우리가 주장하고자 하는 가설이 맞다고 하는 것은 위험하기 때문이다...!)
(모르는 사람이 갑자기 와서 내가 들고 있는 포켓몬빵이 본인 것이라고 하는 상황에서, 실제로 그 빵이 그 사람 것일 가설을 대립가설이라 할 수 있다. 그렇다면 그 사람은 충분한 근거를 들어 그 가설을 주장해야한다. 만약 충분한 근거를 주장하지 않는다면 난 그냥 미친사람 취급하고 가 버릴 수도 있고, 반대로 그 사람이 우긴다고 한다면 내 빵을 갖고 싶어 징징대는 어린아이와 다를게 없다. )
완전 말장난이다,,,~
3-(2) 검정통계량과 기각역의 결정
우리는 모집단의 일부분인 표본으로부터 검정의 결론, 즉 H0를 기각하거나 H0를 기각하지 않고 유지하는 결정을 내리게 되는데, 이때 이용되는 표본의 함수, 즉 통계량을 검정통계량(test statistic)이라고 한다. 위의 예에서는 추출된 40명의 콜레스테롤 수치의 평균 x̄가 검정통계량이 된다.
이 검정통계량 x̄을 관측하여 그 값으로부터 μ에 대한 두 가설 중 하나의 결론을 내리게 된다.
이 예에서는 x̄의 값이 200에 비해 상당히 작을 때, 즉 적당한 c에 대해서 x̄≤c일 때 H0를 기각하게 된다. 이때 구간 R: x̄≤c 를 기각역(critical region)이라고 하는데, 이 기각역의 올바른 선택이 검정의 가장 주요한 부분이라고 할 수 있다.
이때 선택된 기각역의 H0하에서의 확률(α=P(x̄≤c))을 유의수준(significance level)이라고 한다.
표본의 크기가 크다는 전제하에 검정통계량 x̄를 표준화시키면, H0가 맞을 때

가 성립한다.
이때 검정을 시행할 때 보통 x̄에 대한 기각역을 구하기보다는 바로 Z를 계산하여 검정의 결론을 내리는 경우가 흔하다. 그러므로 검정통계량으로 Z을 사용하고 기각역을

로 표현하는 것이 일반적이다.
이와 같은 검정을 표준정규분포를 갖는 확률변수 Z를 붙여서 Z-검정(Z-test)이라고 하기도 한다.
3-(3) 유의확률(Significance Probability)
앞서 배운 내용에 따르면 표본으로부터 계산된 Z의 값으로부터 기각여부를 결정한다. 여기서 더 나아가 이 값으로 부터 기각을 한다면 얼마나 확실하게 기각할 수 있는가를 판단할 수 있다.
위 예시에서 검정통계량 Z에 대한 기각역으로 R: Z≤-1.645를 구하였다. 이때 z=-2.22를 얻었다면 z=-1.95로 얻어졌을 떄와 마찬가지로 H0를 기각하게 되지만, 전자가 더 확실히 H0를 기각할 수 있다. 왜냐하면 z=-2.22 이하의 값을 갖는 것이 z=-1.95 이하의 값을 갖는 것보다 더 드문 일이기 때문이다.
마찬가지로 상대적으로 더 작은 유의수준하에서도 기각이 가능하게 하는 값을 얻었을 때 더 확실하게 H0를 기각할 수 있다. 왜냐하면 유의수준이 작아질수록 기각역이 줄어들기 때문이다.
만약 유의수준을 α=0.05에서 α=0.025로 줄인다면 그에 맞는 기각역도 R: Z ≤ -1.645에서 Z ≤ -1.96으로 줄어든다. 이때 z=-2.22는 두 기각역에 모두 포함되지만 z=-1.95는 그렇지 않다.
일반적으로, 얻어진 Z의 값으로부터 기각할 수 있게 하는 최소의 유의수준이 작을수록, 더욱 확실하게 H0를 기각하여 H1를 채택하게 된다.
위의 예시에서 z=-2.22로 구해졌다고 하면, 이 값을 포함하는 기각역 중 가장 작은 유의수준을 주는 기각역은 R: Z -2.22가 된다. 이때의 유의수준은 P(Z ≤ -2.22) = 0.0132이다. 이때 얻어진 확률 0.0132를 z=-2.22의 값을 주는 자료에 대한 P-값(P-value) 또는 유의확률(significance probability)이라고 한다.
P-값(혹은 유의확률): 주어진 검정통계량의 관측치로부터 H0를 기각하게 하는 최소의 유의수준을 말한다.
통계학 파이썬을 이용한 분석(자유아카데미)
지금까지의 내용은 표본의 크기가 크다는 것을 가정하여 중심극한정리에 의해 표본평균 x̄의 분포가 정규분포가 된다는 사실을 이용하였다. 하지만 표본의 크기가 작은 경우에는 중심극한정리를 사용할 수 없다.
대신 이를 대체할 수 있는 t 분포(t distribution)을 설명하고자 한다.
4. t 분포(t distribution)
표본의 크기가 큰 경우에는

에서 σ 대신 표본표준편차 s로 대체하여도 그 분포가 큰 영향을 받지 않았다.
하지만 표본의 크기가 작은 경우에는 위와 같이 대체하게 되면 표준정규분포와는 다른 형태를 띄는데, 이런 경우에 그 분포를 t 분포라고 한다.
정규모집단

으로부터 추출된 표본을 X1,...Xn이라고 할 때, 표본평균과 표본분산을

이라고 정의하면, 표준화된 확률변수
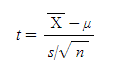
는 자유도가 (n-1)인 t 분포를 따른다고 하고, 이를 기호로써 t(n-1)로 표현한다.
t 분포는 1908년 영국의 화학자인 고셋(W.S. Gosset)이라는 사람의 필명을 따서 t 분포 앞에 스튜던트(Student)를 붙여 스튜던트 t 분포라고도 한다.
t 분포는 표준정규분포와 같이 0을 중심으로 대칭이고, 종 모양을 하는 분포이다. 다른 점은 양꼬리부분에 상대적으로 많은 확률이 존재해서 표준정규분포보다 두꺼운 꼬리를 갖는다는 것이다.

자유도가 커지면 꼬리부분의 확률이 중심으로 모이면서 표준정규분포에 가까워진다.
4-(1) 구간추정
정규모집단에서 추출한 표본으로부터 계산된 통계량

는 자유도가 (n-1)인 t 분포를 따른다.
따라서 μ에 대한 100(1-α)% 신뢰구간은 다음과 같이 정리될 수 있다.

4-(2) 가설검정
표본의 크기가 작은 경우에도 모집단이 정규분포를 따른다면 앞서 설명한 과정과 같이 검정통계량을 얻게 되지만, 모분산이 알려져 있지 않은 경우에 검정통계량

은 더 이상 정규분포를 따르지 않고, 자유도가 n-1인 t 분포를 따르게 된다.
이 t-검정의 경우에도 단지 기각여부뿐 아니라 관측값으로부터 P-값을 계산하여 검정의 결론을 뒷받침하는 것이 바람직하다. 하지만 표준정규분포표와는 달리 t 분포표에는 몇 개의 α값에 대해서만 상위 α의 확률을 주는 값이 주어져 있기 때문에 정확한 P-값을 구하기가 어렵다. 하지만 다양한 통계 패키지를 통해 P-값을 얻는 것이 가능하다.
네이버 블로그에서 티스토리로 이전하여 이전에 썼던 글들을 복사 붙여넣기 하고 있는데 양식이 많이 달라서 어렵다...ㅠ